Automatic knowledge extraction
The primary aim of this subproject is to develop new advanced models of and methods for automatic extraction of concepts and information about concepts from text. The models and methods should, in principle, be applicable to a large number of languages, but we primarily focus on developing tools that work on Danish language texts.
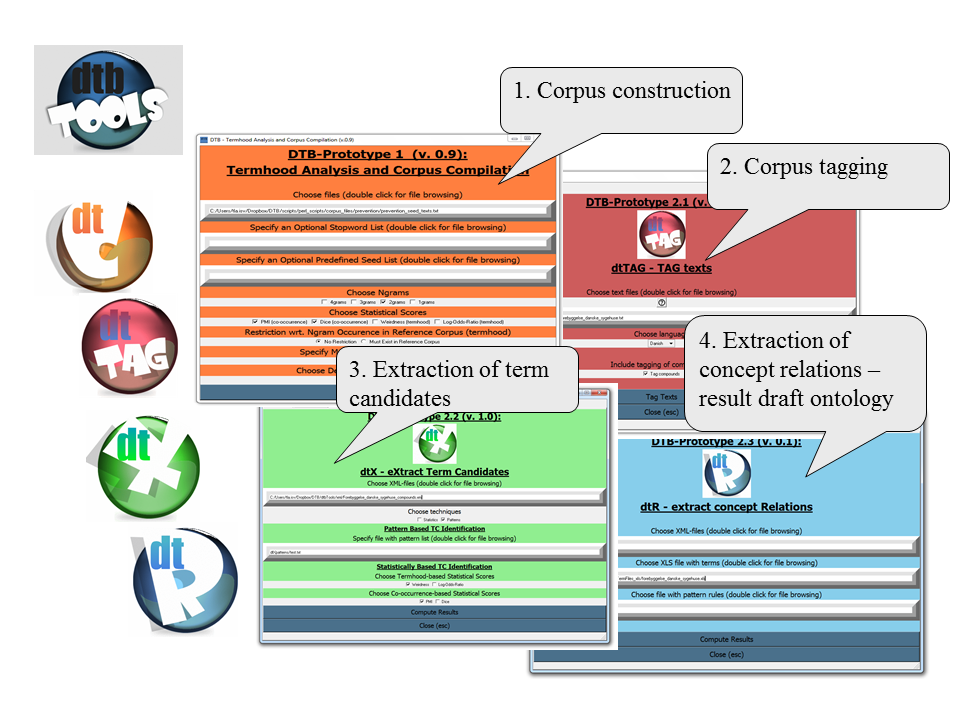
In order to fulfill this aim, the project is developing a prototype for corpus compilation and processing, which, on the basis of domain texts collected from the Internet, can automatically extract terms and relations and produce a draft version of a terminological ontology.
The subproject develops two prototypes (see e.g. Lassen, 2012, pp.218-230): a corpus compilation tool (dtCrawler) and a corpus processing tool (dtbTOOLS). The first tool allows us to compile domain corpora from the web, combining a selection of statistical measures with known terminology input and set operations. The second tool allows us to tag the corpora, and extract knowledge in the form of term candidates as well as relations between them from the corpora, using a combination of POS-patterns, rules, statistical measures, and a combined ranking score.
dtbTOOLS will be made available for download here.