Automatisk vidensekstraktion
Det primære mål i dette delprojekt er at udvikle nye, avancerede modeller, metoder og værktøjer til automatisk ekstraktion af begreber og information om disse fra tekster. Disse avancerede modeller og metoder kan, i princippet, bruges på mange sprog, men i første omgang fokuserer vi på at udvikle værktøjer som kan håndtere danske tekster.
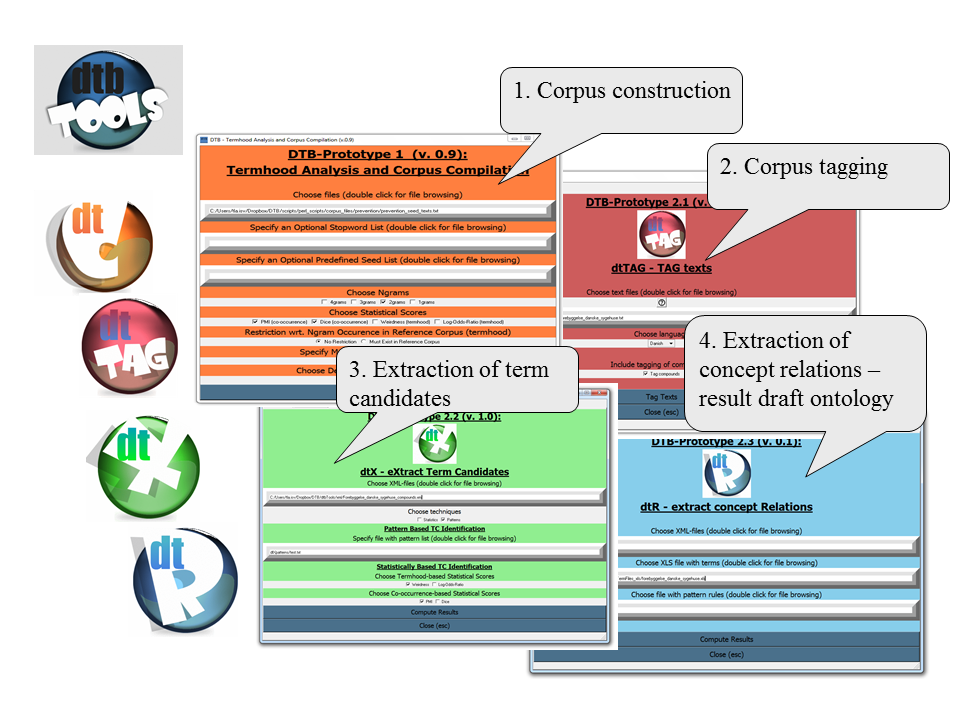
Projektet udvikler prototypeværktøjer til kompilering og behandling af domænespecifikke fagsproglige tekstkorpora fra internettet. Værktøjerne indsamler tekster på Internettet; udtrækker termer og begrebsrelationer automatisk og producere udkast til terminologiske ontologier.
Der udvikles to prototyper (se fx. Lassen, 2012, s.218-230): et korpuskompileringsværktøj (dtCrawler)og et korpushåndteringsværktøj (dtbTOOLS).
- dtCrawler indsamler fagkorpora fra nettet ved at kombinere statistiske data med terminologiske data og mængdeoperationer.
- dtbTOOLS opmærker korpora med lingvistiske markeringer og udtrækker viden i form af termkandidater og relationer mellem disse fra korpora ved at anvende POS-mønstre, regler, statistiske data og et rangordningssystem.
dtbTOOLS vil blive stillet til rådighed på et senere tidspunkt.